Basic Querying with PostgreSQL
In the previous post, we looked at data normalization in PostgreSQL. In this tutorial, we’ll expand on our work to write queries that answer questions about the data.
This tutorial uses a database of famous people. I make no claims about the reliability of the data, however, the information in the database will be very useful for the purposes of this tutorial. The main table is called [person] which which depends on data in two ancillary tables, [occupation] and [nationality].
Before starting, please download and import this practice database into PostgreSQL.
Data Exploration
The first thing we should do is try to get a better picture of the data we will be working with. To do this, we can join the related tables and look at the first ten rows with the following query:
SELECT * FROM person p
INNER JOIN occupation o ON o.id= p.occupation_id
INNER JOIN nationality n ON n.id = p.nationality_id
ORDER BY estimated_iq_score desc
LIMIT 10Because we know our data is highly normalized and complete, we can use an INNER JOIN without worrying about losing information. In many cases in the real world however, we would need to use a LEFT JOIN, RIGHT JOIN, or FULL OUTER JOIN depending on the situation. We will look at different JOIN types in another tutorial.
Here are the results of our query:
| id | name | n_id | o_id | e_iq | o.id | o.name | n.id | n.name |
|---|---|---|---|---|---|---|---|---|
| 60 | Leonardo da Vinci | 19 | 6 | 220 | 6 | scientist | 19 | Italy |
| 50 | Johann Wolfgang von Goethe | 2 | 9 | 210 | 9 | unknown | 2 | Germany |
| 81 | Emanuel Swedenborg | 18 | 11 | 205 | 11 | philosopher | 18 | Sweden |
| 48 | Gottfried Wilhelm von Leibniz | 2 | 11 | 205 | 11 | philosopher | 2 | Germany |
| 10 | John Stuart Mill | 1 | 11 | 200 | 11 | philosopher | 1 | England |
| 7 | Sir Francis Galton | 17 | 6 | 200 | 6 | scientist | 17 | British |
| 65 | Kim Ung-Yong | 20 | 9 | 200 | 9 | unknown | 20 | Korea |
| 21 | Thomas Wolsey | 1 | 14 | 200 | 14 | politician | 1 | England |
| 90 | William James Sidis | 26 | 9 | 200 | 9 | unknown | 26 | USA |
| 70 | Hugo Grotius | 9 | 7 | 200 | 7 | jurist | 9 | Netherlands |
This looks interesting, but it looks like there are a lot of extra identifier columns that will not be useful to us for answer questions. Let’s cut them out and boil our query down to the essentials.
SELECT p.name,n.name,o.name,p.estimated_iq_score
FROM person p
INNER JOIN occupation o ON o.id= p.occupation_id
INNER JOIN nationality n ON n.id = p.nationality_id
ORDER BY estimated_iq_score desc
LIMIT 10| name | nationality | occupation | estimated_iq_score |
|---|---|---|---|
| Leonardo da Vinci | Italy | scientist | 220 |
| Johann Wolfgang von Goethe | Germany | unknown | 210 |
| Emanuel Swedenborg | Sweden | philosopher | 205 |
| Gottfried Wilhelm von Leibniz | Germany | philosopher | 205 |
| John Stuart Mill | England | philosopher | 200 |
| Sir Francis Galton | British | scientist | 200 |
| Kim Ung-Yong | Korea | unknown | 200 |
| Thomas Wolsey | England | politician | 200 |
| William James Sidis | USA | unknown | 200 |
| Hugo Grotius | Netherlands | jurist | 200 |
Creating a View
Now that we have our query in a form that we can use it to answer questions, let’s go ahead and save it as a view since we’ll be referring to it frequently. Note that in creating a view each column will need a distinct name, so we will need to alias the nationality and occupation columns as shown below. Additionally, we can remove the ORDER BY clause from our view since it adds unnecessary processing time to our view.
CREATE VIEW famous_people AS
SELECT p.name,n.name nationality,o.name occupation,p.estimated_iq_score
FROM person p
INNER JOIN occupation o ON o.id= p.occupation_id
INNER JOIN nationality n ON n.id = p.nationality_idAnswering Questions with SQL
Now that the view is created let’s answer some questions using SQL. Using the view name in place of the table name. Use the following syntax to construct your queries:
SELECT [column name] FROM [table name] WHERE [column name] = [value]How many people in the group are from the USA?
Consider the following query:
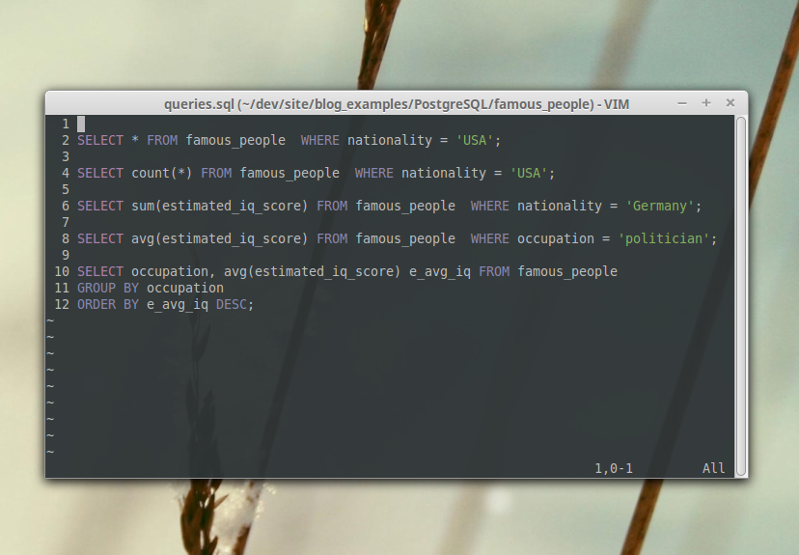
SELECT * FROM famous_people WHERE nationality = 'USA'We could apply the query and count the result, but this would be impractical for larger data sets. Instead, let’s apply the count function.
SELECT count(*) FROM famous_people WHERE nationality = 'USA'This immediately returns the answer we are looking for: 31.
What is the sum of the estimated IQ scores of people from Germany in the dataset?
We could write a query to list the all the people from Germany and add up their estimates manually, but using the sum function on the estimated_iq_score column will bring us the result we are looking for: 2769.
SELECT sum(estimated_iq_score) FROM famous_people WHERE nationality = 'Germany'I almost didn’t want to include this question because we would almost never want to take the sum of IQ scores in real life unless we were trying to find an average (and there is already a function for average called avg), however, this is just for learning purposes and we don’t have any other columns that are summable.
What is the average estimated IQ score for politicians in this dataset?
144.4
SELECT avg(estimated_iq_score) FROM famous_people WHERE occupation = 'politician'Which occupation in this dataset has the second highest estimated IQ score on average?
For this question, we will need to write a query to group the results together by occupation and apply the averge aggregator to the estimated_iq_score column. We will want to alias the column so that we can use it for sorting.
SELECT occupation, avg(estimated_iq_score) e_avg_iq
FROM famous_people
GROUP BY occupation
ORDER BY e_avg_iq DESC| Occupation | Estimated Average IQ |
|---|---|
| jurist | 200 |
| bouncer | 195 |
Interestingly, the occupation with the second highest average estimated IQ score in our dataset is bouncing.
Conclusion
Congratulations! This completes the tutorial. You are well on your way to becoming a master of SQL.